04 / 核心概念
AI Token 是什么? · 信息图
帮助销售/售前建立能对客户复述的选型框架,而非算法原理
使用 ← → 键或滚动翻页
本次材料偏实战沟通,不做算法论文式展开
理解 Token 在计费、吞吐和配额中的角色
模型原厂、云平台、聚合平台的核心差异
首字延迟、RPM、TPM、模型精度的业务含义
把业务需求翻译成模型能力和选型方向
适用对象:销售 / 售前 · 培训时长:60 分钟 · 信息截止:2026-05-17
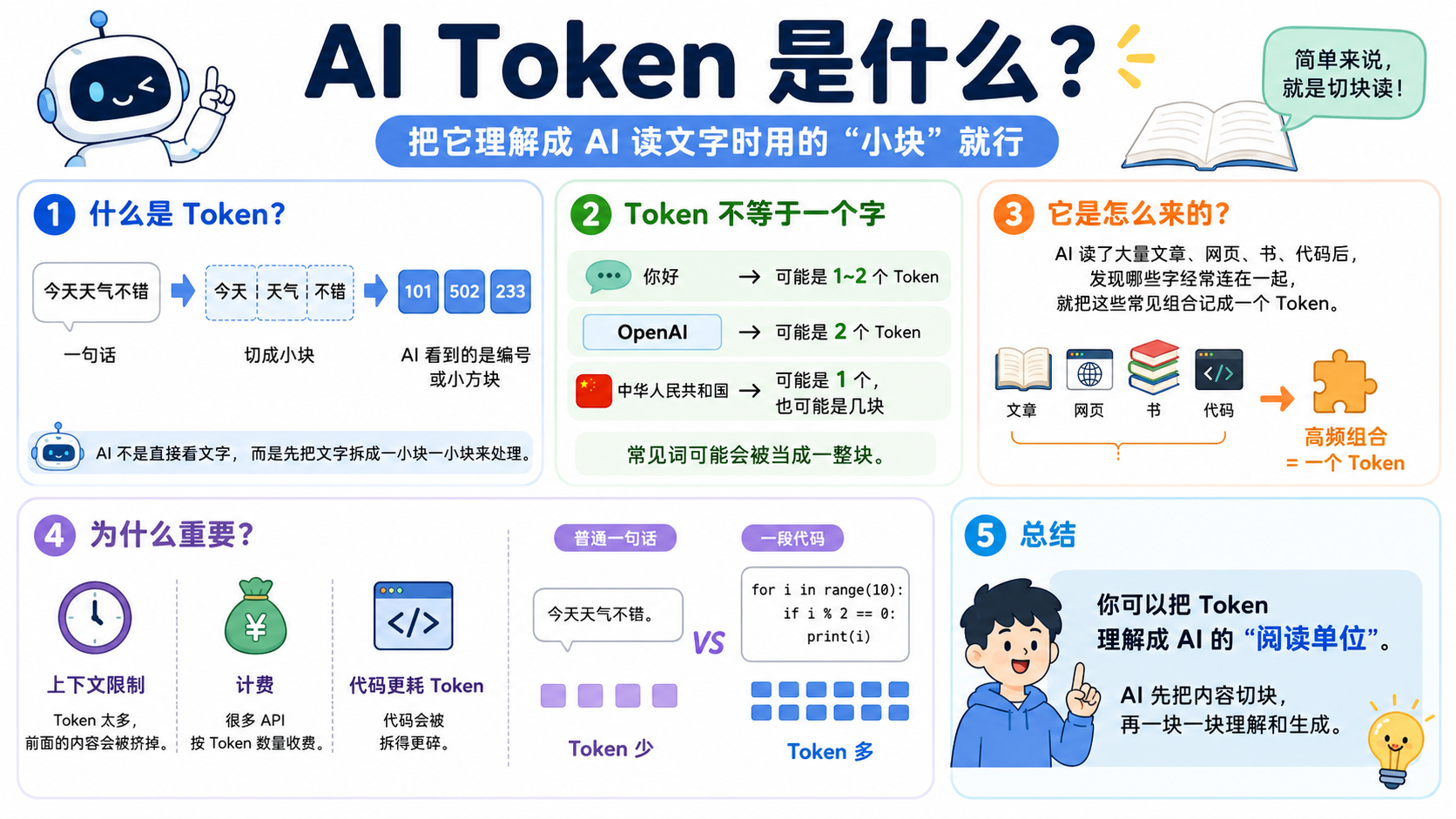
Token 是模型处理内容的基础计量单位,既影响计费,也影响吞吐和配额
Token 既是计费单位,也是容量单位,还是售前沟通里的业务翻译器
输入/输出/缓存/批量,口径可能不同
TPM、TPS、上下文长度、批处理规模
模型大小不同,总成本会差很多
上下文越长、输出越多、并发越高,体验越易受影响
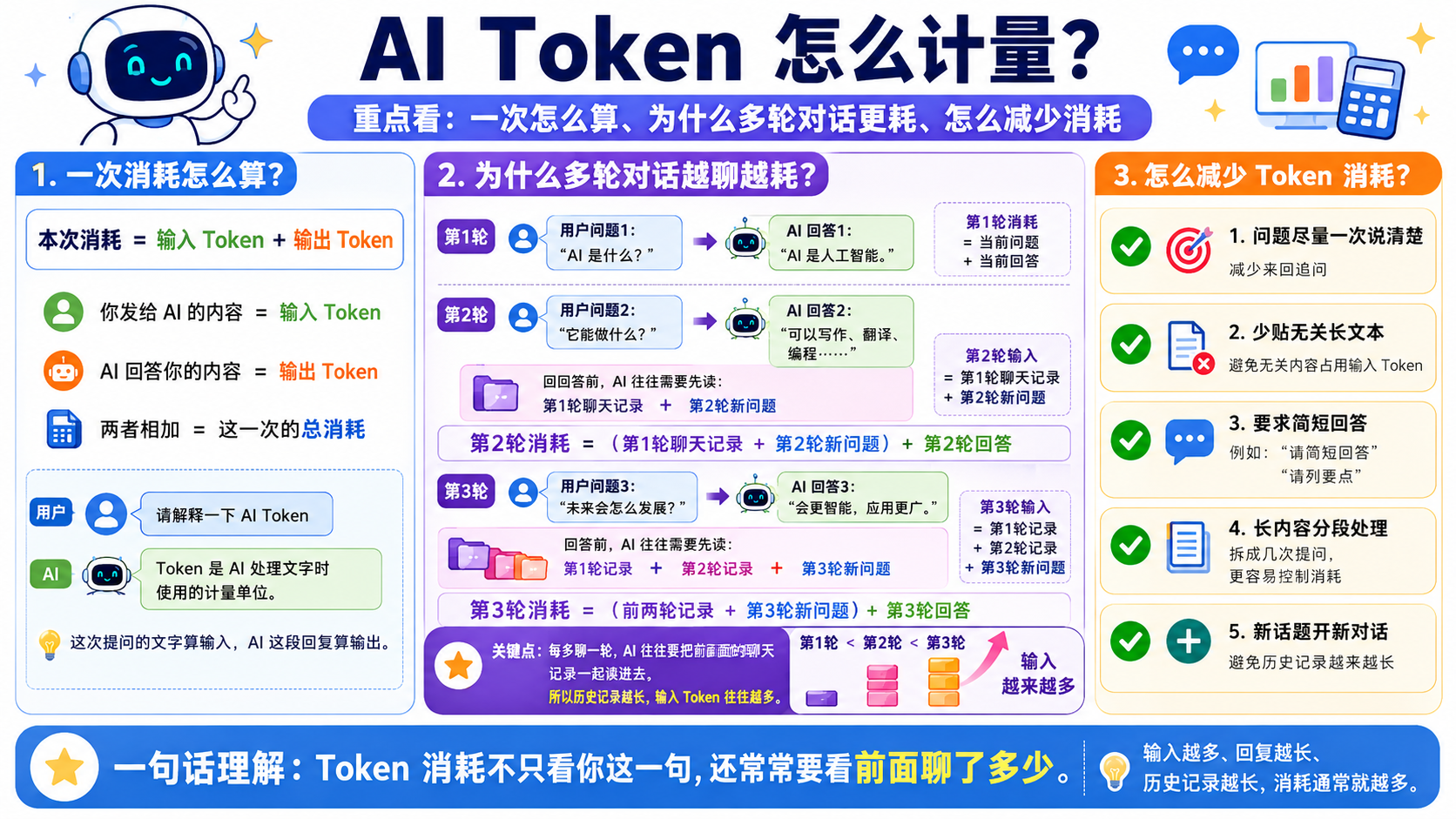
每次 API 调用的输入都包含全部历史会话——这是最容易忽略的成本因素
每次 API 调用,以上全部内容都要重新发送
第 1 轮
~500
tokens 输入
第 5 轮
~2,500
tokens 输入
第 10 轮
5,000+
tokens 输入
缓解手段:提示缓存(Prompt Caching)
可减少重复传输开销,但计费模型本质不变——每一轮的输入仍包含全部历史
Token 是把能力、成本、容量放到同一套尺子里
输入 / 输出 Token 会影响总成本,不同模型、不同输出长度,成本差异显著
TPM、上下文长度、批处理规模都与 Token 相关,长文本和大并发场景最先被打满
长上下文、高输出会影响速度,首字延迟决定用户的第一感受
不只分国内外,更要分模型原厂、云平台、聚合平台——三类平台卖的核心价值不同
代表平台
OpenAI, Anthropic, DeepSeek, MiniMax
模型迭代快、原生能力强
代表平台
Azure, 百炼, 千帆, Bedrock
合规、审计、企业接入更完整
代表平台
OpenRouter, 七牛云, 硅基流动
选择多、切换快、成本灵活
国内平台核心吸引力:更容易落地在本地业务环境,尤其是数据安全、审计、私有化部署
| 类别 | 代表平台 | 核心优势 | 典型局限 |
|---|---|---|---|
| 云平台 | 阿里云百炼、百度千帆、火山方舟、腾讯混元 | 企业接入、权限治理、区域与合规支持 | 模型选择未必覆盖全球最全 |
| 模型厂商 | 智谱、MiniMax、DeepSeek | 原生模型能力清晰,部分场景更新快 | 周边企业能力可能不如大云平台 |
| 聚合平台 | 七牛云 AI 大模型推理、硅基流动 | 多模型统一接入、切换快、选型灵活 | 合规和服务口径需逐项确认 |
国外平台更适合强调两件事:顶尖模型首发和生态速度;某些模态或专业能力的领先性
| 类别 | 代表平台 | 核心优势 | 典型局限 |
|---|---|---|---|
| 模型原厂 | OpenAI、Anthropic、Google Gemini | 模型领先、文档完整、能力首发快 | 数据区域、合规、企业采购有门槛 |
| 云平台 | Azure OpenAI、Amazon Bedrock | 企业级交付、区域治理、配额管理 | 价格和可用性受云平台策略影响 |
| 聚合平台 | OpenRouter、Together AI、Groq、Replicate | 模型丰富、切换快、可做路由与 fallback | 企业治理与长期 SLA 需单独确认 |
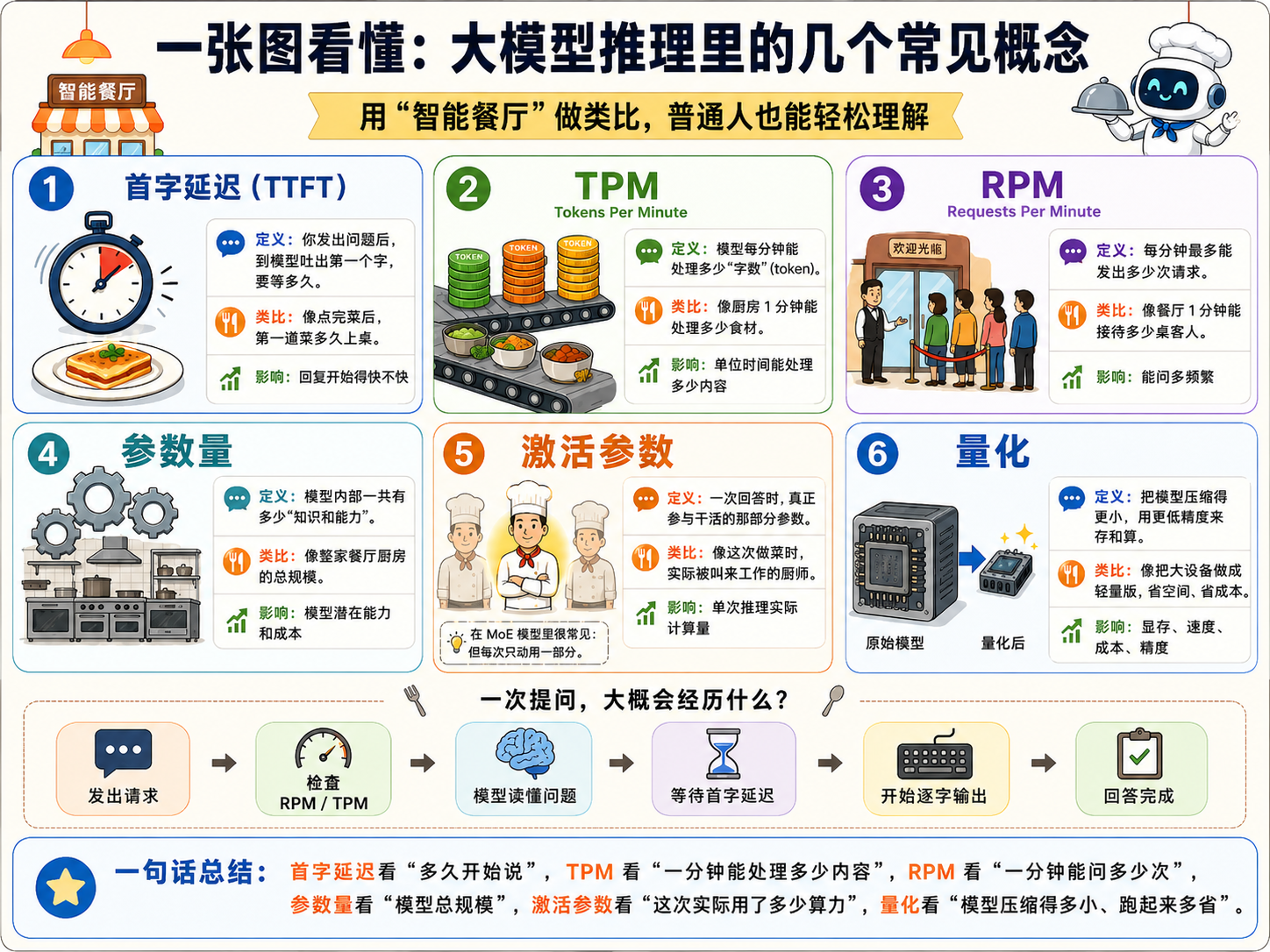
用户发起请求后,到模型开始返回第一个有效 token 或首段可见内容的时间
直接影响"感觉快不快"。客服、编程补全、语音交互中,首字慢比总时长慢更让人觉得卡
模型大小、服务层级、请求排队、上下文长度、工具调用、平台当前负载
业务含义
决定"第一感觉快不快"
测3类典型请求:短问答、长上下文问答、带工具或复杂推理;并区分 P95 / P99
Requests Per Minute
每分钟允许或可承载的请求数
决定"高峰时会不会频繁被限流"
Tokens Per Minute
每分钟能处理的 Token 数量
决定"长文本和大并发时扛不扛得住"

更像在某个任务、某种语言、某个评测方法下的综合表现,包括理解、推理、生成质量、事实性、代码能力、多模态能力
模型架构、训练数据、任务类型、语言、提示词、上下文质量、是否使用检索增强
榜单决定"值不值得试"
业务测试决定"能不能上"
决定"结果值不值得业务信任"
文本生成是大多数项目底座,但不是所有项目都该上最强模型
OpenAI:GPT-5.5 / o3 / o4-mini
Anthropic:Claude Opus 4.7 / Sonnet 4.6
Google:Gemini 3.1 Pro
字节:豆包 2.0 (Seed-2.0 Pro / Lite / Mini)
腾讯:混元 TurboS 阿里:千问 API (Qwen3.5)
Meta:Llama 4 Scout / Maverick
阿里:Qwen3.5 DeepSeek:V4 / R1
智谱:GLM-5 MiniMax:M2.5 月之暗面:Kimi K2.6
通常还需要搭配 Embedding / 检索能力,关注正确率、上下文长度、私有代码安全
| # | 模型 | 智能 | 价格/1M | t/s | 延迟 |
|---|---|---|---|---|---|
| 1 | GPT-5.5 (xhigh) OpenAI | 60 | $11.25 | 64 | 76.3s |
| 2 | GPT-5.5 (high) OpenAI | 59 | $11.25 | 66 | 29.0s |
| 3 | Claude Opus 4.7 (max) Anthropic | 57 | $10.94 | 52 | 23.7s |
| 4 | Gemini 3.1 Pro Preview Google | 57 | $4.50 | 125 | 31.2s |
| 5 | Kimi K2.6 Kimi | 54 | $1.71 | 71 | 2.9s |
| 6 | MiMo-V2.5-Pro Xiaomi | 54 | $1.50 | 52 | 3.0s |
| 7 | Grok 4.3 (high) xAI | 53 | $1.56 | 94 | 7.1s |
| 8 | Qwen3.6 Max Preview Alibaba | 52 | $2.92 | 38 | 3.4s |
| 9 | DeepSeek V4 Pro (Max) DeepSeek | 52 | $2.17 | 33 | 2.0s |
| 10 | GLM-5.1 Z AI | 51 | $2.15 | 55 | 1.4s |
| 11 | MiniMax-M2.7 MiniMax | 50 | $0.52 | 48 | 2.1s |
| 12 | DeepSeek V4 Flash DeepSeek | 47 | $0.18 | 94 | 1.2s |
Kimi K2.6、Qwen3.6 Max、DeepSeek V4 Pro、GLM-5.1 智能指数均超 50,与海外旗舰差距持续缩小
DeepSeek V4 Flash 仅 $0.18/1M tokens,智能指数 47 — 适合高并发低价值场景
MiniMax-M2.7 $0.52/1M,智能指数 50 — 国内最高性价比之一
国内模型首字延迟普遍 < 3s,GLM-5.1 仅 1.4s,适合实时对话场景
海报、角色图、广告素材、封面图、概念图
代表:GPT Image、Imagen、FLUX、Stable Diffusion
商品图改版、角色图迭代、海报扩展、风格迁移
代表:OpenAI 图像编辑、Ideogram、SD 生态
客户如果要批量营销素材,先看风格一致性、出图速度和商用授权;如果要高审美创作,再看风格控制上限
图生图比纯文生更可控——客户更在意"基于原图改得像不像、稳不稳",而非从零生成得多惊艳
| # | 模型 | Elo |
|---|---|---|
| 1 | GPT Image 2 (high) OpenAI | 1338 |
| 2 | GPT Image 1.5 (high) OpenAI | 1266 |
| 3 | Gemini 3.1 Flash Image Google | 1264 |
| 4 | Gemini 3 Pro Image Google | 1221 |
| 5 | Seedream 4.0 ByteDance | 1195 |
| # | 模型 | Elo |
|---|---|---|
| 1 | GPT Image 1.5 (high) OpenAI | 1263 |
| 2 | GPT Image 2 (high) OpenAI | 1251 |
| 3 | Gemini 3 Pro Image Google | 1238 |
| 4 | Gemini 3.1 Flash Image Google | 1232 |
| 5 | HunyuanImage 3.0 Tencent | 1222 |
Seedream 4.0(字节)文生图第5,HunyuanImage 3.0(腾讯)编辑第5且为开源最佳
文生图开源第一:HiDream-O1-Image-Dev Elo 1184
编辑开源第一:HunyuanImage 3.0 Elo 1222
播报、配音、语音助手、电话机器人
代表:OpenAI Speech、Azure Speech、ElevenLabs
品牌声线、数字人播报、影视配音替换、多语种配音
代表:ElevenLabs Cloning、Azure Custom Neural Voice
核心指标
自然度 / 稳定性 / 语种 / 授权
音色克隆一定要提前谈清楚授权、声音权、录音样本质量和合规审批
| # | 模型 | Elo |
|---|---|---|
| 1 | Suno V5.5 Suno | 1210 |
| 2 | Mureka V8 MiniMax | 1190 |
| 3 | Suno V5 Suno | 1175 |
| 4 | Lyria 3 Pro Google | 1146 |
| 5 | Suno V4.5 Suno | 1116 |
Mureka V8(MiniMax)排名第二,Elo 1190,与 Suno V5.5 仅差 20 分
Suno 系列占据 Top 5 中 3 席,持续领跑音乐生成赛道;Google Lyria 3 Pro 新入榜即排第四
音乐生成更关注风格匹配度、节拍稳定性和商业授权,Elo 差距 20-30 分在实际听感上差异不大
创意提案和短内容工业化——广告短片、剧情片段、视觉草稿
代表:Runway、Google Veo、MiniMax 视频、Kling
已有素材的动态扩展——静态图转动态视频、镜头预演
业务里真正要看
主体稳定性
镜头一致性
可编辑性
生成速度
定位:加速前期创意和批量内容生产,不要包装成替代完整制作团队
| # | 模型 | Elo | 价格 |
|---|---|---|---|
| 1 | Seedance 2.0 720p ByteDance Seed | 1223 | — |
| 2 | HappyHorse-1.0 Alibaba-ATH | 1214 | 即将上线 |
| 3 | Kling 3.0 Omni 1080p KlingAI | 1106 | $16.80/min |
| 5 | Veo 3.1 Google | 1102 | $24.00/min |
| 7 | Sora 2 OpenAI | 1088 | $6.00/min |
| # | 模型 | Elo |
|---|---|---|
| 1 | Seedance 2.0 720p ByteDance Seed | 1179 |
| 2 | HappyHorse-1.0 Alibaba-ATH | 1164 |
| 3 | grok-imagine-video xAI | 1088 |
| 5 | Veo 3.1 Google | 1083 |
字节 Seedance 2.0 和阿里 HappyHorse-1.0 包揽文生视频和图生视频双榜第一,Kling 系列多型号入榜
核心不是只有聊天模型——售前最容易被低估的场景
架构示意
用户提问
Embedding 检索
Rerank 排序
LLM 生成回答
引用溯源
关键指标
正确率、长上下文、私有代码安全
关键指标
数据安全、引用准确性、系统集成
不是都要上旗舰模型——轻量场景用 mini / flash / lite 更合适,复杂推理再用旗舰
这是"文本 + 图像 + 视频 + 语音"的组合型场景
文案、脚本、话术
主图、素材、活动页
短视频脚本、直播话术
配音、多语种客服
核心概念:内容工业化生产,而不是单一模型炫技
典型需求
剧本、角色、分镜、配音、视频
模型组合
文本+图像+语音+视频
典型需求
字幕、本地化、镜头延展、海报
模型组合
语音识别+翻译+图像+视频
典型需求
品牌声线、播报、互动营销
模型组合
TTS+克隆+视频生成
客户真正关心:风格一致性、人物稳定性、出片速度、版权风险、批量成本
金融
政企
医疗
售前提醒:高合规客户通常先问安全边界,再问模型能力。云平台治理能力往往和模型能力同等重要
先按任务选能力,再按时延和并发选平台,最后按预算和合规收窄范围
问答/写作 → 文本生成 | 知识库 → +Embedding/Rerank | 营销 → 文本+图像+视频 | 语音 → TTS+ASR+克隆
对话实时 → 首字延迟 | 多用户并发 → RPM | 长文本大输出 → TPM | SLA 要求 → 服务层级
预算敏感 → mini/flash/聚合 | 合规敏感 → 云平台/私有化 | 快速试错 → 聚合平台
核心任务是什么?
效果/速度/成本优先级?
并发和单次消耗多大?
数据区域和审计有硬要求吗?
先验证还是直接上线?
客户的问题表面在问价格和参数,实质通常在问"风险、确定性和可落地性"
价格差异不只来自模型本身,还来自交付方式、服务层级、区域、并发配额、企业治理能力。建议把单价和效果、时延、稳定性、合规一起看。
不同模型在中文、代码、多模态、长上下文上的强项不同;同一模型在不同平台上的服务层级、限流、工具链也会影响效果。
演示通常是低并发、短上下文、理想网络;上线受 RPM、TPM、峰值流量、上下文长度和服务等级影响,生产环境要单独评估。
不一定。开源省掉部分调用费,但会带来算力、部署、运维、优化和人员成本。对稳定性和合规要求高的场景,闭源或云平台未必更贵。
一句话记住的选型原则
先看任务类型,再看模型名字
先看效果和时延,再看单价
高并发看 RPM,大上下文看 TPM,交互体验看首字延迟
知识库项目一定把 Embedding / Rerank 一起考虑
高合规行业里,部署和治理与模型一样重要
Q & A